This may seem obvious.
But what needs to be communicated with?
What is appropriate to spend the extra money to purchase the optional
Ethernet port on? When two products are
available that meet the specification, and one has data logging capabilities
(and costs more), is it worth getting the device with the data logging?
Controller
Communications
This is the most obvious one to connect. Connecting the controller allows for remote
uploading and downloading of the controller database, plus monitoring of the
controller’s current operation. If the
signal system includes a central system, then the signal can be configured to
provide data on scheduled intervals back to the central system.
The data fed to the central system can include alarms,
traffic counts, current status of the controller (what phases are green,
yellow, red etc.) and other information.
In some cases, the central system can be set up to log this data. The central system that I use logs a great
deal of information.
One key piece of information that is logged, is the time
served for each split division. This is
done whether the signal is in coordination, or free. This is logged as historical information, so
it is easy to run a report to look at what was happening recently for the
amount of time served for any or all movements at the signal. This can be helpful to determine what a
reasonable cycle time may be for a signal.
It can also be helpful in determining if there is a problem with a
signal. Citizens will call and make
statements about long waits for a green, or that a green was never served for a
side street. I have had phone calls
where a citizen stated that they waited 25 minutes for a green. There may be some truth to that statement,
but having the ability to look back on the split division logs allows me to
confirm that there was, or was not a problem at the specific time that the
citizen stated that they had the undue wait.
The logging of data also helps identify problems with the
signal operation. If a controller
develops internal problems, that information may be part of the alarm stream
that is reported back to the signal. We
recently had a controller develop a problem with the TS2 communications and the
controller started showing thousands of SDLC detector failures an hour. Since the detector failures are not a
critical SDLC problem for the controller, the signal kept chugging along. A quick review of the alarm logs showed that
there was a problem with the signal. The
problem was manifesting itself by causing the signal to extend, and serve
movements that had no cars. Based on the
field review of the equipment, it was determined that there was a problem with
the controller, and the controller was swapped out. The BIU’s were swapped out, and the problem
continued. The problem could have been
the CPU or the SDLC communications on the 2070-2N connector. Bench testing will help determine that. But having the controller connected to the
central system gave us the first piece of information that there was a problem.
Another key piece of information is when a signal goes into
all-red flash. When a signal goes into
red flash, the central system knows this within a second or two, and within
another few seconds the central system sends out an email to key personnel stating
that the signal is in red flash. In some
cases, I have seen signals in red flash for several days before a citizen calls
in the problem.
Monitor Communications
There is a new generation of monitors generally called smart
monitors. These include advanced
features for data logging, communications ports, and special programming to accommodate
things like flashing yellow arrow configurations. Many agencies are still holding on to their
old monitors. The old monitors work, but
may not provide the same level of information that the more modern monitors
provide.
I have had citizen calls where the citizen states that they
are waiting at an intersection, and they are never getting a green. By checking on the central system, I can see
what the system states the controller is telling the system. By checking remotely on the monitor software,
I can confirm that the field indications are consistent with the central
system.
The monitor software allows for remote viewing of the signal
inputs and outputs, along with the line voltages. The picture below shows the Reno AE software
talking to a Reno 1600Ge MMU. This is a
static picture, so you can’t get a real feel for the information. The line voltages are dynamically being
updated. The current greens, yellows and
reds are showing up on the screen.
 |
| Reno A&E PC software view of monitor operation |
Another feature of the monitor software is that when a
signal goes into flash, the monitor software can provide very good information
about why the signal is in flash. Is the
problem a controller issue, a cabinet issue – that requires somebody to replace
a component in the signal cabinet, or a problem with an indication that
requires a bucket truck?
Problem Controllers
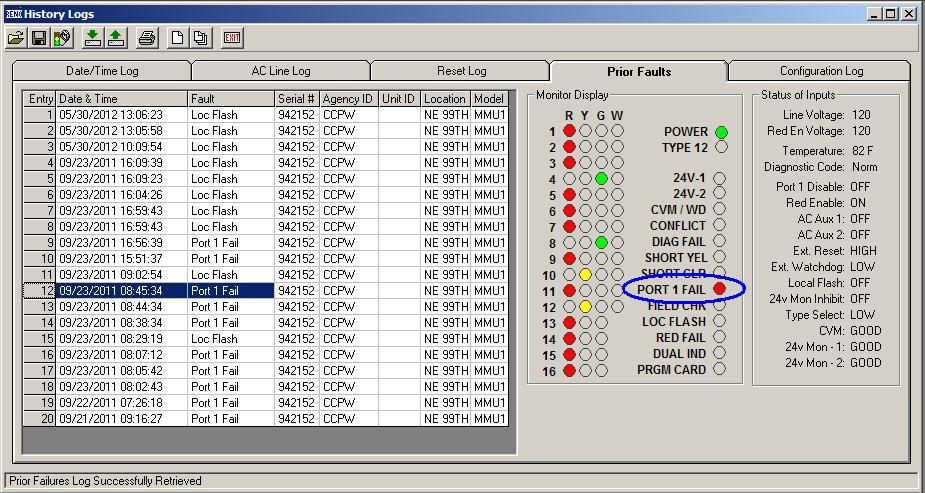
In the example below, the prior faults log is shown for a
Reno 1600Ge MMU. In this example, the
controller CPU was dying.
 |
| Reno MMU reporting a Port 1 failure |
A little explanation of the standards is probably in order
here. The NEMA TS2 standards require
that if a controller exhibits a Port 1 failure 3 or more times in a 24-hour
period, that the monitor latch the signal in all-red flash. The Port 1 is the main port out of the
controller that provides the SDLC communications. The controller sends out command frames, and
gets response frames from the peripheral devices. This is a very important communications
node. A Port 1 fail would typically be a
failure of specific command frames from the controller. These frames are generally routed around the controller,
Terminals and Facilities (T&F, also known as the load bay) BIU’s and the
MMU. When a Port 1 failure occurs, the
monitor puts the signal in flash. If the
Port 1 failure clears, the monitor will allow the controller to automatically
come out of flash. If 3 port 1 failures
occur in a 24-hour period (also called in some controllers as 3 critical SDLC
failures in 24 hours), then the monitor will transition the signal into all-red
flash and keep it there until a technician comes by and services the cabinet.
Because the TS2 standard requires that 3 3 port 1 failures
in 24 hours occur before the monitor locks the system in all-red flash, you can
have a situation where the signal will transition in, and out of flash on its
own. This is not like a CVM fault, or
24V fault, where you can put in jumpers on the MMU board to latch a CVM or 24V
fault. This is a programming issue in
the monitor. To deal with this, many
controller software packages allow the user to modify this by having the
controller internally latch the signal in red flash when 1, 2 or 3 (user
specified) Port 1 failures occur in a 24 hour period. This will allow the controller to keep track
of its own problems, and upon seeing a Port 1 failure, keep the signal in red
flash. This should allow the controller
to not bounce in and out of red flash multiple times before going into locked
red flash.
In the example above, the controller’s CPU was not working
properly. The controller would lock up,
and create a Port 1 fail which the monitor reacted to, then the controller CPU
would restart itself, then lock up, creating another Port 1 fail, restart and
create another Port 1 fail, at which time the MMU would latch the red flash.
In the attached example, you can see that the controller
went into red flash 3 times 8:38 AM and 8:45 AM, then a technician cleared the controller
failures, restarted the controller, and the signal worked normally until it
went into 2 Port 1 failures (in and out of red flash 2 times) between 3:51 PM
and 4:56 PM. This looks odd, because it
looks like it went into red flash twice before it locked this time. The reality is that I had a replacement CPU
in my hand, and had just opened up the cabinet door at 4:56 PM, and the signal
went through its restart procedure. I
then placed the signal into cabinet red flash, replaced the CPU, and restarted
the signal with the new CPU.
Determining Conflicts
Another example of how the monitor software can help
determine what is going on is when a conflict occurs. In the example below, phases 2 and 6 were
green, and the monitor showed that phases 3 and 4 showed green and reds on
simultaneously. This may not be the best
example to show, but this was a case where one of the field technicians was
working inside a cabinet, and momentarily contacted the greens for phase 3 and
4 to ground, which caused the signal to go into flash.
 |
| Reno MMU reporting a conflict |
While this may not be the best example, it does show
information. I got the email from the
central system that the signal was in flash, and then almost immediately out of
flash. I pulled up the monitor PC
software, and looked at what the monitor said it was doing. By the time I got the monitor PC software
running, the signal was out of flash. I
called the signal tech and asked what was going on. He was a little sheepish, but told me what
had happened. Nobody got hurt, and the
tech got a good reminder that you need to be careful when working around the
contacts in a cabinet.
Oddities
One thing that you may see occasionally is the signal going into all-red flash because of a short yellow. This is rare. Most traffic signal controllers do not want to have a yellow change interval less than 3.0 seconds. Some controllers will allow yellow change interval settings at less than 3.0 seconds, but only if the controller is programmed in one place to allow less than 3.0 seconds, and in another place to specifically program a phase to have less than 3.0 seconds. I have been a traffic engineer for a long time, and have found exactly zero signals where I would time the signal at less than 3.0 seconds of yellow change interval.
The MMU also monitors the yellow change interval. In the event that the yellow change interval is less than 2.7 seconds, the monitor will place the signal into all-red flash. This can also be overwritten in the monitor settings, but like the short yellow in the controller, I have found exactly zero signals where I would override this setting in the field.
Below is an example from a traffic signal controller in a cabinet that is in a test environment. This was forced to a short yellow as a part of testing out some features in the controller and monitor.
If for some reason the signal actually experienced a yellow of 2.7 seconds or shorter, the signal would automatically go into all-red flash.
 |
| Reno MMU reporting a short yellow fault |
Having the communications in the field allows the technician to know what has happened to the signal before leaving the desk. This helps the technician to determine what level of equipment and expertise will be able to fix the problem.
The last example for monitors shows a known problem with the
TS2 specification.
This is a minor
irritant from a maintenance standpoint, but it may be a bigger deal if you are
a pedestrian.
 |
| Reno MMU reporting dual indication fault |
The NEMA TS2 specification requires that the monitor look at
the time that the Flashing Don’t Walk (FDW) is on, and off. The specification essentially requires that
the FDW be turned on for half a second, then turned off for half a second. The monitors generally allow for some slop in
the SDLC communications frames, by allowing extension either of the on or off to
6/10th of a second. This is
because the controller is driving the outputs, and in the event that a frame is
missed, the status of the indication won’t change.
Occasionally, the monitor will see the FDW on or off for
7/10th of a second. This is
seen as a problem by the monitor, and the monitor transitions the signal into
all-red flash immediately. This extra
1/10th of a second happens very rarely, but it happens. In my experience, when a TS2-1 traffic signal
is left in ped recall, this will occur about once a month, on one of the
pedestrian movements that is in recall.
Video Detection Communications
Cameras fail. Nature
sometimes helps. What appears to be a
good viewing angle when you set it up may be very different at night, or in the
rain.
Cameras fail
The following three pictures show older generation cameras
that have problems with the video feed images to the video processor. When the cameras are not working properly,
and feed bad information to the video processor, this defines the term “garbage
in, garbage out”.
 |
| Problem camera. Note that the picture is divided where the bottom of the screen shows the far advance, and the left side of the screen shows what should be on the right. The video detection zones are correct, if the camera were working properly. |
|
 |
| Problem camera. Note how the picture is divided at the bottom of the screen. The bottom of the screen shows what should be the far horizon of the camera. |
 |
| Problem camera. Note how the picture is divided about in the middle of the screen. The bottom half of the picture should be above the top half. The zones are correct, assuming that the camera is working properly |
These cameras are being replaced. The key here is, this signal was not
connected to any system. It was a lone
signal, with no communications. The only
reason we knew about the problem is because a citizen got frustrated and called
in that the signal wasn’t operating properly.
If this signal were connected to the system, we would have been able to
look at the operation and see what was working properly and what wasn’t.
Once a week, or more frequently, I spend a chunk of time and
pull up multiple signals and look at what they are doing.
In a past job, I found another unique type of problem. The video detection was not working
properly. It didn’t take long to figure
out what was causing the problem. It
probably would have taken a little less time, if I had already had my first cup
of coffee before I started looking at the cameras. In that situation, the video detection
cameras were mounted on Astrobrac connections to the mastarms. During the night, the Astrobrac straps
slipped on the mastarm, and the camera swiveled from being on top of the
mastarm to being on the bottom of the mastarm, hanging down instead of up. This caused the camera to go from the normal looking
at traffic approaching eastbound to the intersection, to upside down, looking
at traffic departing the intersection westbound. The stopbar detection that the camera was
driving didn’t work so well.
Sometimes Nature Helps
Below is a video I took where we had a spider who created a
web over the video detection camera lens.
You can see how the spider is causing false calls to the controller.
Below is a video of a poorly placed camera, but showing how
the glare of headlights is causing false calls on the detectors.
The key here is to watch the detection zones for the cars
traveling north (almost straight up) in the picture. The glare from the southbound headlights does
not cause false calls in the two northbound detection zones.
The two northbound detection zones are count stations. I experimented with how to deal with the oblique
angle, and headlight glare. The remote
video feed allowed me to modify the detectors and try things to see what
happened in multiple weather and lighting scenarios.
There are actually two detectors in each northbound lane of
travel. The large, visible, box is a
directional detection zone. This box is
looking only for traffic heading northbound.
Any glare from a southbound vehicle’s headlights don’t cause a true
condition in the Boolean logic in the detection scheme. When a northbound vehicle causes a True
condition in the box, and then the vehicle crosses an invisible line at the far
north end of the box, then the detection system places a call.
Having remote communications to the video detection system
allows me to test a variety of ideas in vehicle detection strategies, and
observe them in various weather and lighting conditions. Based on the glare on the wet pavement from
the overhead luminaires I moved the detection zones around into the glare, out
of the glare, and observed how the system operated. Based on this, I was able to hone in on a
detection strategy for this particular brand and model of video detection
system that works for multiple situations.
Conclusions
These are just a few examples of how communicating to the
field equipment can provide significant benefits.
The main benefit is being able to see what is going on from
your desk. In my case, I can VPN into
the system and see what is going on.
Last year, I was visiting family in Idaho, and received a call that
there was a problem with a signal that was under construction. I pulled out my laptop, connected it to my
MiFi card, and was on the system within 5 minutes – from Lewiston Idaho. It took about another 3 minutes to figure out
that the contractor had shifted traffic from the normal lanes to another area
of the pavement that had no detection. I
modified the radar stopbar detection and in about 15 minutes total, I was back
on the phone to the construction manager telling him what I had done. He reported to me that the signal appeared to
magically begin working properly.
Magically. I like
that. Magic is how things are explained
that happen mysteriously that we can not explain with other knowledge or
understanding.